

From ransomware, to spyware and banking trojans, the types of malware threats are many. Yet the one threat that seems to be posing the greatest challenge to organizations and their cybersecurity solutions is unknown malware.
This is because the means that have most typically been used to counter cyber threats to date remain insufficient when it comes to unknowns:
Signature-based: traditional antivirus solutions usually lean on such technique. With this technique, key data from given files is signed, and so for next times files are matched with the same signature, those will be classified as malicious. The key data is usually strings, or other byte sequences of code piece. This approach is not adequate since it can only be used for known attacks, based on known pieces from current existing malicious files. With unknown attacks, the signature won’t match anything.
Heuristic-based: this is an advanced technique for signatures. Instead of using a fixed signature, some parts of the signature can be random, and so it doesn’t necessarily have to be an exact signature match. The downside is that it is time consuming and works better with known than unknown files.
Sandboxing: involves running suspicious files within an isolated environment for a few minutes, while dynamically testing what the file is doing while it is running, in order to understand whether it is malicious or not without impacting the production environment. In most cases, such implementations would be in detection mode, as it is time consuming to analyze and get a verdict, and so it delays on-going organizational work (e.g. receiving emails with attachments). In addition, many malware campaigns are well familiar with such platforms, and have many anti-VM capabilities to bypass detection by such solutions. For example, in a case where there is a match with the drivers, hostname or username used by sandboxing platforms, the malware won’t execute its malicious activities.
Machine learning: a branch of artificial intelligence (AI). It allows computers to learn, by feeding large amounts of feature-based data to the ‘machine’ to teach it how to identify malicious files, based on certain file features. While more advanced and coming ahead of signature, heuristic, and sandboxing, one of its main downsides is that it relies on such feature engineering – meaning, it only uses a small part of the file structure, and is based on known attack vectors that are represented by those features. As a result, most of the data goes unprocessed, unanalyzed, and the correlations between the data points do not undergo analysis either. This means that machine learning is partial by its very nature and can never properly or fully pick up on, nor prevent unknow files. In addition, classical machine learning algorithms tend to not be very much accurate, mostly in domains that are not easy to solve, such as cybersecurity. That leads to moderate recall (detection rate) and false positive rate on unseen samples that were not involved in the training phase of the algorithm.
Accordingly, none of these approaches fare well in today’s world that is primarily battling new and unseen malware variants.
The Ever-Growing Threat of Unknowns
Yet, the demand for beating the threat of unknowns is only getting bigger as the threat continues to grow at a dizzying pace. Consider these staggering stats, for example:
- There are over 100 unknown malware attacks hitting an organization every hour; and
- Over 360,000 new malicious files appearing daily.
It’s no surprise, then, that in a recent report, it was found that of the 300 global IT and InfoSec professionals surveyed, 49% believe that unknown malware is the greatest risk to their organization.
The Unique Abilities of Deep Learning Cybersecurity
There is one approach, though, that overcomes the pitfalls of other means, as it is inherently designed to handle unknown malware. This approach is deep learning cybersecurity.
For a quick recap – deep learning is the most advanced branch of artificial intelligence today. Its learning method is inspired by the way the human brain learns – taking in all the data and learning from it automatically and intuitively.
Deep learning is the first — and currently the only — learning method that is capable of training directly on raw data. There is no need for feature engineering with deep learning, as is needed with machine learning. To the contrary, deep learning can dive into the raw data of the file, without explicitly being told to pay attention to certain features, which have been specified by human experts.
Moreover, deep learning scales well to hundreds of millions of training samples. As the training dataset gets larger and larger, deep learning continuously improves. And the third aspect of deep learning that makes it unique is its ability to pick up on patterns and correlations in the raw data that are too complex for any human or AI to pick up on.
Thus, its unique approach to training and learning endows it with both intuitive and predictive capabilities – which is probably one of the most critical capabilities for picking up on unknown threats. For, if you can’t ‘know’ in advance what it is, you must be able to predict what it is.
Machine Learning vs. Deep Learning
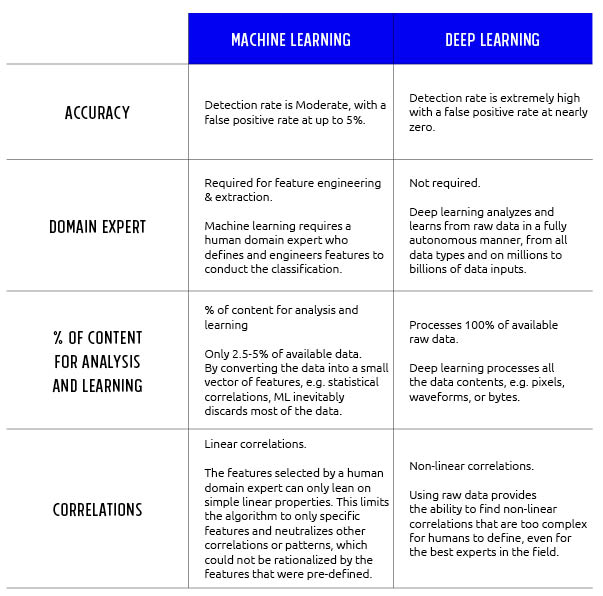
Thus, deep learning is unique among all other cybersecurity approaches and is best positioned for handling unknowns. In fact, deep learning has a specific expertise with unknown files, delivering the highest detection and prevention rates along with unmatched low rates of false positives.
Deep Instinct Is Leading the Deep Learning Cyber Security Revolution
Deep Instinct is proud to make available the first cybersecurity solution that harnesses the power of deep learning to prevent, detect, and respond to unknown threats (and known, of course), to protect any device type, running on any operating system, and against any file-based and even file-less attack. Deep Instinct not only provides autonomous cybersecurity in preventing cyber-attacks from executing on your devices, but also the malware analytics and threat classification you need to be well informed. Key features of our automatic threat analysis include an intuitive security management console, attack chain identification, advanced threat analytics, and in depth threat analysis reporting.
