Machine Learning
What is Machine Learning?
Machine learning is the leading subfield of AI (artificial intelligence), in which computers can learn by themselves without being explicitly programmed.
AI methods based on machine learning have dominated AI in the 2000s, and they have outperformed AI that is not based on machine learning.
How Does Machine Learning Work?
Machine learning happens through the use of data known as training samples. Machine learning requires both training data and a mechanism for feature extraction.
In order to train a machine learning model, you first need data samples. These are essential ingredients without which machine learning can’t happen. Each image in a dataset will need to be labeled or classified. The labels in the dataset will guide the training, which is known as supervised training.
So is there such a thing as unsupervised training? Yes, it is possible to train a machine learning module using training data that doesn’t have any associated labels. Most real-world scenarios, though, use supervised training, because if labeled data is available, it usually gets better results. Unsupervised learning has huge untapped potential as well because most of the data in the world is unlabeled.
Feature Extraction
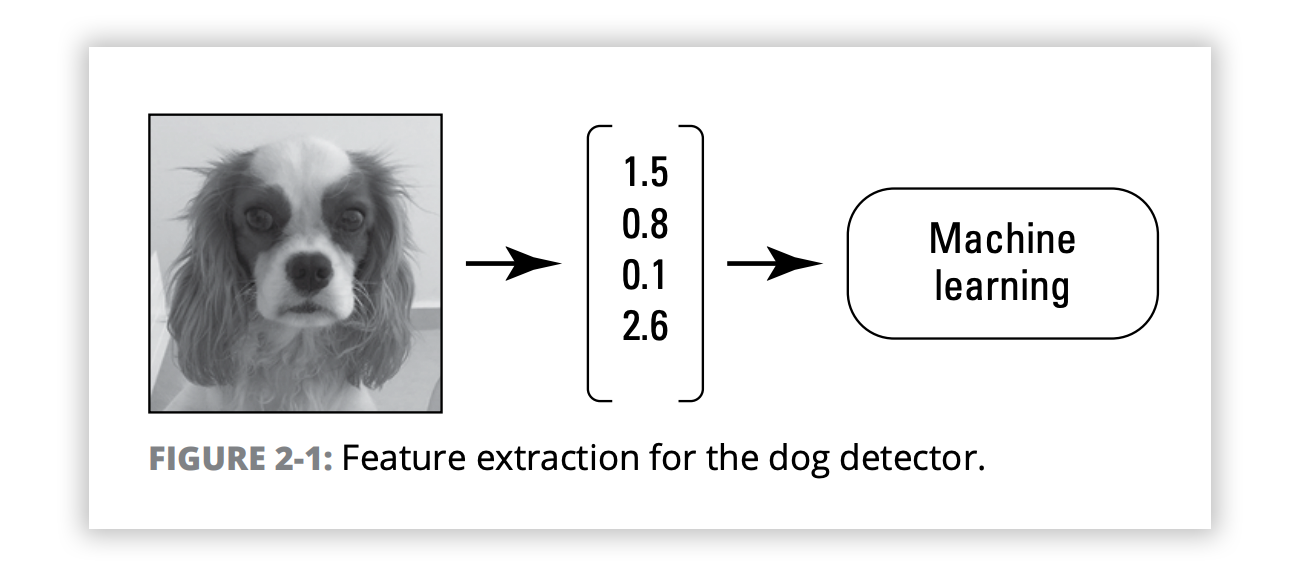
In traditional machine learning, you can’t simply feed raw data into the machine learning module. The machine is aware of the pixels, but for those pixels to be useful in training the model, there must be a feature extraction phase (or feature engineering). Feature extraction is the process of extracting a set of predefined properties or features from the raw data.
To perform feature extraction, you first need a domain expert to specify what the important features are. As the name suggests, the domain expert is somebody who has expertise in the specific problem domain. For problems involving images, you need an image processing expert who can analyze the problem domain and the samples, and then determine the features to extract.
In a typical case, you start with raw data and extract a few tens of features, perhaps hundreds, or maybe even thousands. Each input sample is converted to a vector of numbers, each corresponding to a feature. This vector is then fed into the machine learning module.
Limitations of Machine Learning
Machine learning is successful, to be sure, but that doesn’t mean it is without limitations.
Reliance on Feature Extraction
One of its major limitations is its reliance on feature extraction. In this process, human experts dictate what the important features or properties of each problem are.
Consider the challenge of face recognition. You can’t just feed the raw pixels of an image into a machine learning module. Instead, those pixels must first be converted into specific features that the machine learning module will be on the lookout for, such as distance between pupils, proportions of the face, texture, and color.
Certainly, face recognition through this approach is pretty impressive. But the fact is, by focusing on those very specific aspects defined by human experts through feature extraction, the approach is ignoring most of the raw data. As useful as the selected features may be, this method for face recognition misses the rich, complex patterns in the data.
Machine Learning and Cybersecurity
Basic machine learning (ML)-based solutions either protect too much— slowing down the business and flooding your team with false positives—or lack the precision, speed, and scalability to predict and prevent unknown malware and zero-day threats before they have infiltrated your network.
While ML-based tools can take minutes to hours to detect unknown malware, Deep Instinct detects and prevents unknown malware in <20ms. Machine learning uses manual and supervised datasets fed into models by humans (manual feature engineering) to allow systems to make decisions with less human interaction.


