

By Jonathan Kaftzan, VP Marketing
With today’s blog post – I am excited to get us started on a four-part series based on our newly published book, Deep Learning for Dummies by our very own Dr. Eli David. We thought it would only be fair to share some of the insights here with you.
To get us started, part 1 of this series will give you a brief intro to deep learning and then dive a bit deeper in its evolution, how it differs from other artificial intelligence (AI) technologies, and its real-world application.
The Magic of Deep Learning
“Deep learning is the area of artificial intelligence where the real magic is happening right now,” Forbes.
Deep learning (DL) is at the cutting of artificial intelligence (AI), driving innovation across many different commercial applications.
With the ever-growing availability of more and more data, and deep learning’s unique ability to leverage it for ever more intuitive, accurate, and real-time insights – the opportunities for taking AI to where it’s never been before have never been greater.
But, before we get into the wonders of DL – let’s take a look back to where it all got started – so we can better understand why it’s so important not only for other commercial applications, but specifically for revolutionizing cybersecurity.
The First Step in the Evolution: AI and Machine Learning
The term artificial intelligence (AI) was originally coined by the pioneering computer scientist John McCarthy in the 1950s and refers to machines that can perform tasks that are characteristic of human intelligence.
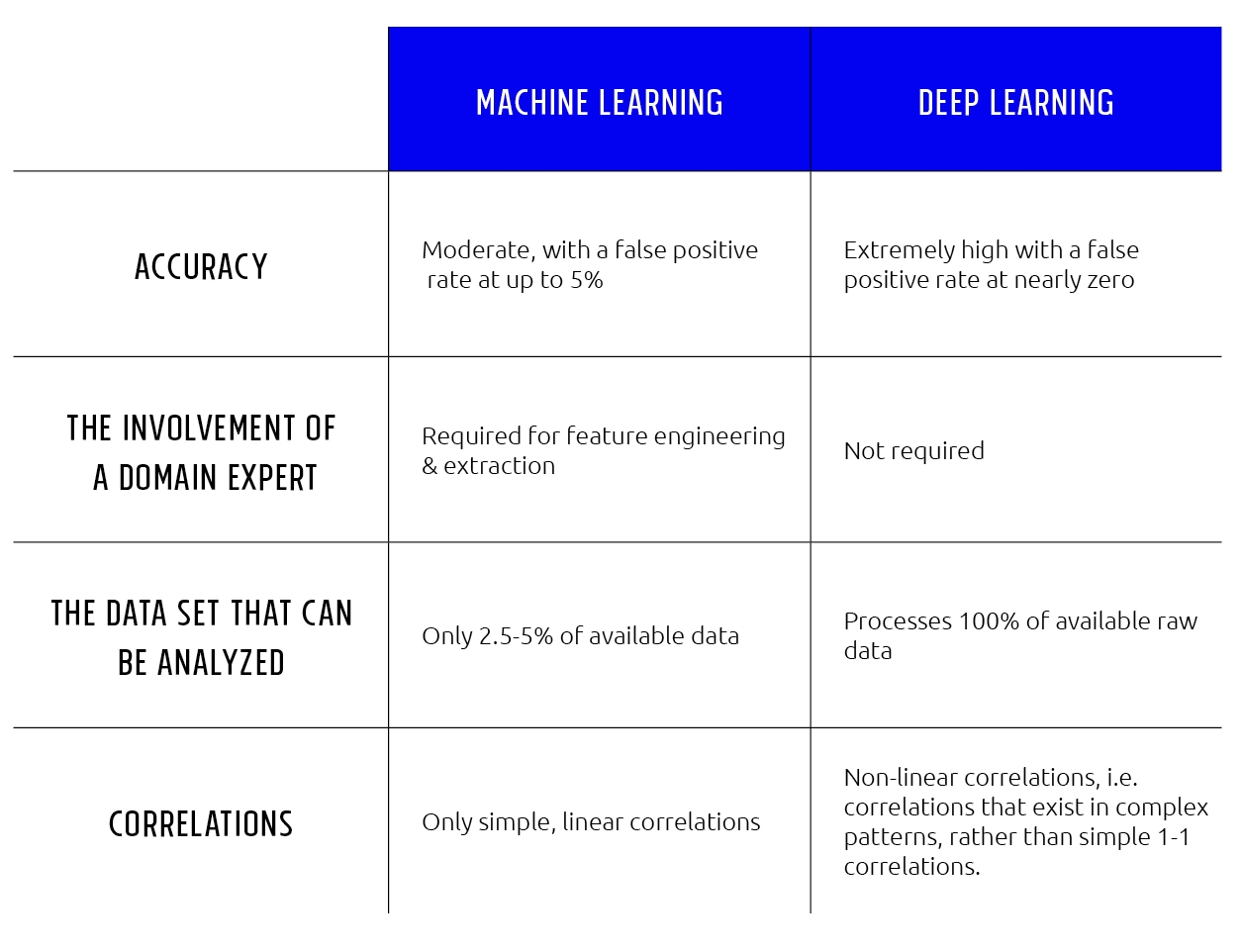
The leading subfield of AI today is known as machine learning (ML), where an algorithm is “trained” to learn and adjust itself to improve without being programmed. While indeed an advancement over traditional AI methods, it is not without its limitations. For example, one of the major limitations is its reliance on feature extraction. This is a process by which human experts dictate what the important features or properties of each problem are.
As such, this approach ignores most of the raw data. As a result, ML is limited, missing the rich and complex patterns available in complete data sets.
Going to Uncharted Territory with Deep Learning
Deep learning, also known as deep neural networks, however, is different. It is the most advanced subset of AI, going further than machine learning, and taking inspiration from the way the human brain works, where ‘neurons’ (algorithms) mimic the biological structure of the brain.
The biggest difference between machine learning versus deep learning is that deep learning is the first — and currently the only — learning method that is capable of training directly on raw data.
There is no need for feature extraction with deep learning. Moreover, as opposed to machine learning, deep learning scales well to hundreds of millions of training samples. As the training dataset gets larger and larger, deep learning continuously improves.
Machine Learning vs. Deep learning: An Overview
The Unprecedented Success of Deep Learning
During the past few years, deep learning has achieved a 20-30%improvement in most benchmarks of computer vision, speech recognition, and text understanding. This represents the greatest leap in performance in the history of AI and computer scienceץ
There are two major drivers for this success. The first is the improvement in algorithms, which, until a few years ago, could only train “shallow” neural networks. But, today’s improved methods allow for the successful training of very deep neural networks – where, the deeper the network (i.e. the more layers stacked up) – the more complex and refined the data processing.
The second and even more important driver is the use of graphics processing units (GPUs). These days, nearly all deep learning training is conducted on GPUs made by Nvidia.
So, for example, when seeking to train a deep learning framework on new capabilities, whether for image processing, speech recognition, or cybersecurity – new capabilities can go to market much much faster.
The Commercial Application of Deep Learning
With its effectiveness and high levels of accuracy, the adoption of deep learning is accelerating, and we see it already being promoted with multiple commercial applications:
- Autonomous cars: for automatically unlocking cars with face recognition, alerting drivers to potential hazards, and gaze tracking for driver distraction alerts;
- Healthcare & genomics: to predict the outcomes of genome alterations and provide a more precise understanding of diseases;
- Agriculture: to predict crop yields based on the analysis of masses of satellite images;
- Image recognition: sorting and classifying millions of uploaded images for more accurate search results;
- Personal (virtual) assistants: for speech recognition to better understand spoken commands and questions and predicting user needs and preferences.
Deep Learning for Cybersecurity
Indeed, the unprecedented capabilities of deep learning present exciting opportunities for many commercial applications.
One area that is just now joining the deep learning revolution is cybersecurity. With more and more attacks coming from unknown, unseen, or recently mutated sources – current AV methods can’t keep up. Only deep learning can handle the task. And, why is that? Well . . . you’ll need to stay tuned. We’ll cover that in our forthcoming posts in the series.
Meantime, to learn more about how deep learning works and why it’s revolutionizing how cybersecurity is done, we invite you to download the Deep Learning for Dummies book here.
 hbspt.cta.load(2183098, '39c4111b-3a7a-4680-a472-137ad9c7b4c4', {});
hbspt.cta.load(2183098, '39c4111b-3a7a-4680-a472-137ad9c7b4c4', {});
Stay tuned for part 2 of the series - Understanding Neural Networks and how it evolved into deep learning.